New York City Taxi and For-Hire Vehicle Data
On August 12th, 2016, Mark Litwintschik
published a blog post called
1.1 Billion Taxi Rides with MapD & 8 Nvidia Pascal
Titan Xs
.
We reproduced the approach provided by this post to
create a benchmark using Ibis with
New York City Taxi and For-Hire Vehicle Dataset
.
The data acquisition and cleaning used by Mark Litwintschik was described in his another blog post on 13th Febrary, 2016, called A Billion Taxi Rides in Redshift .
The mentioned blog post was based on another blog post published by Todd W. Schneider called Analyzing 1.1 Billion NYC Taxi and Uber Trips, with a Vengeance . The repository that contains the scripts and explanations about how to download and clean the data can be accessed at @toddwschneider's GitHub repo .
Also, both the two Mark's blog post, mentioned before,
give more extra details to prepare the data that should
be used to load the data to OmniSciDB
database.
All the code used to replicate the data acquisition and cleaning, mentioned before, and the current benchmark scripts are stored into Ibis-benchmark repo . For information about how to replicate this benchmark, check out the README.md file.
This benchmark aims to show the performance in time for
some expressions using Ibis with
OmniSciDB and Pandas.
Before start, there are some termilogies used in this document that is explained here to help the reading.
IPC: Inter Process Communication. OmniSciDB uses Apache Thrift for IPC.Cursor: Cursors are used by database programmers to process individual rows returned by database system queries.CPU: Central Processing Unit.GPU: Graphics Processing Unit.Ibis: Python Data Analysis Productivity Framework.
This benchmark measures the execution time (in
seconds) consumed by expressions using
Ibis OmniSciDB backend, with
OmniSciDB CPU and
OmniSciDB CPU, and pure
Pandas.
Ibis OmniSciDB backend can be used
with three differents execution types:
IPC CPU,
IPC GPU and
Cursor.
The expressions used by this benchmark was based on the queries used by 1.1 Billion Taxi Rides with MapD & 8 Nvidia Pascal Titan Xs blog post :
-
t[t.cab_type, t.count()].group_by(t.cab_type)
-
t[ t.passenger_count, t.total_amount.mean().name('total_amount_mean') ].group_by(t.passenger_count) -
t[ t.passenger_count, t.pickup_datetime.year().name('pickup_year'), t.count().name('pickup_year_count'), ].group_by([t.passenger_count, t.pickup_year]), -
t[ t.passenger_count, t.pickup_datetime.year().name('pickup_year'), t.trip_distance.cast(int).name('distance'), t.count().name('the_count'), ] .group_by([t.passenger_count, t.pickup_year, t.distance]) .order_by([t.pickup_year, t.the_count], asc=False),
Where t is the trip
table that contains
New York City Taxi and For-Hire Vehicle Data
.
The time reported here doesn't considerer the time
for data loading, eg. Pandas
read_csv or
OmniSciDB COPY FROM
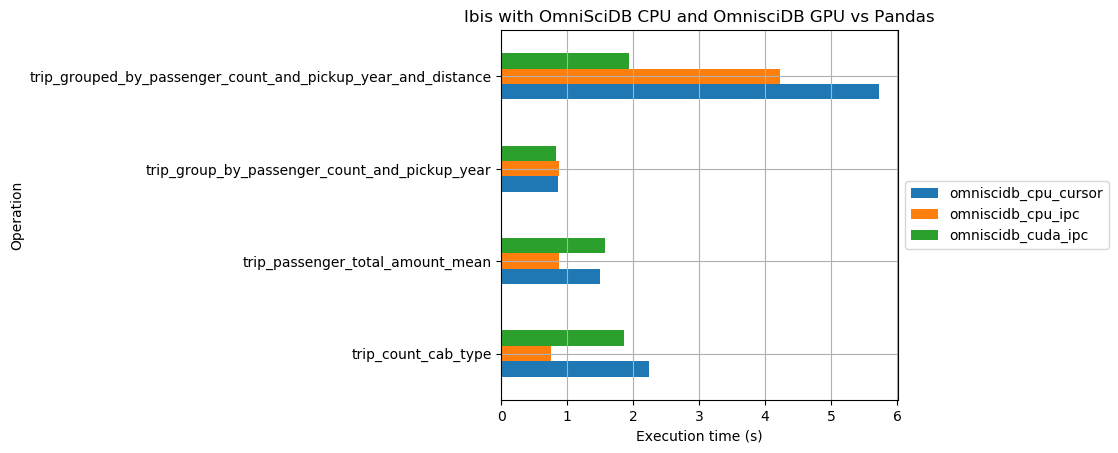
Some considerations about this benchmark:
-
Ibis OmniSciDBbackend, usingcursorexecution type, presents a better performance thanPandasand otherIbis OmniSciDBexecution types for all expressions. -
Ibis OmniSciDBbackend usingIPC GPUpresents a better performance than usingIPC CPUfor all expressions. -
Pandaspresents a better performance thanIbis OmniSciDBbackend usingIPCexecution types for simple expressions.
This benchmarking have been ran in a computer with the following specification:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 2
Core(s) per socket: 24
Socket(s): 1
NUMA node(s): 4
Vendor ID: AuthenticAMD
CPU family: 23
Model: 8
Model name: AMD Ryzen Threadripper 2970WX 24-Core Processor
Stepping: 2
CPU MHz: 1717.658
CPU max MHz: 3000.0000
CPU min MHz: 2200.0000
BogoMIPS: 5987.92
Virtualization: AMD-V
L1d cache: 32K
L1i cache: 64K
L2 cache: 512K
L3 cache: 8192K
NUMA node0 CPU(s): 0-5,24-29
NUMA node1 CPU(s): 12-17,36-41
NUMA node2 CPU(s): 6-11,30-35
NUMA node3 CPU(s): 18-23,42-47
MemTotal: 131947616 kB
GPU Information
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 430.50 Driver Version: 430.50 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Quadro RTX 8000 Off | 00000000:41:00.0 Off | Off |
| 34% 47C P0 65W / 260W | 0MiB / 48601MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Quadro RTX 8000 Off | 00000000:42:00.0 Off | Off |
| 35% 53C P0 1W / 260W | 0MiB / 48600MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
Disk Partition Information
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 3.7T 0 disk
└─sda1 8:1 0 3.7T 0 part /work
nvme0n1 259:0 0 953.9G 0 disk
├─nvme0n1p1 259:1 0 100G 0 part
├─nvme0n1p2 259:2 0 1K 0 part
└─nvme0n1p5 259:3 0 853.9G 0 part /